
Hanee' Medhat Shousha
Verified Expert in Engineering
经过认证的Spark开发人员,拥有CEng学位和商业智能文凭, Hanee开发了拥有数百万日用户的企业应用程序.
Expertise
Previously At

经过认证的Spark开发人员,拥有CEng学位和商业智能文凭, Hanee开发了拥有数百万日用户的企业应用程序.
如今,数据的增长和积累速度比以往任何时候都要快. 目前,世界上大约90%的数据是在过去两年中产生的. 由于这个惊人的增长率, 为了维护如此庞大的数据量,大数据平台不得不采用激进的解决方案.
如今数据的主要来源之一是社交网络. 请允许我举一个现实生活中的例子:交易, analyzing, 并使用最重要的大数据响应解决方案之一——apache Spark,从社交网络数据中实时提取见解, and Python.

In this article, 我将教你如何构建一个简单的应用程序,使用Python从Twitter读取在线流, 然后使用Apache Spark Streaming处理推文以识别标签和, finally, 返回热门话题标签,并在实时仪表板上表示此数据.
为了从Twitter获得tweet,您需要注册 TwitterApps 点击“创建新应用程序”,然后填写下面的表格,点击“创建您的Twitter应用程序”.”

其次,转到新创建的应用程序并打开“密钥和访问令牌”选项卡. 然后单击“生成我的访问令牌”.”

您的新访问令牌将显示如下.

现在你已经准备好进入下一步了.
In this step, 我将向您展示如何构建一个简单的客户端,该客户端将使用Python从Twitter API获取tweet并将其传递给Spark Streaming实例. 对于任何专业人士来说都应该很容易遵循 Python developer.
首先,让我们创建一个名为 twitter_app.py 然后我们将在其中添加代码,如下所示.
导入我们将使用的库,如下所示:
import socket
import sys
import requests
import requests_oauthlib
import json
并添加将在OAuth中用于连接Twitter的变量,如下所示:
#将下面的值替换为您的值
Access_token = ' your_access_token '
Access_secret = ' your_access_secret '
Consumer_key = ' your_consumer_key '
Consumer_secret = ' your_consumer_secret '
my_auth = requests_oauthlib.OAuth1(CONSUMER_KEY, CONSUMER_SECRET,ACCESS_TOKEN, ACCESS_SECRET)
现在,我们将创建一个名为 get_tweets 它将调用Twitter API URL并返回tweet流的响应.
def get_tweets():
url = 'http://stream.twitter.com/1.1/statuses/filter.json'
query_data =[(“语言”、“en”)(“位置”,“-130、-20100、50”),(“跟踪”、“#”)]
query_url = url + '?' + '&'.加入((str (t (0 ]) + '=' + str的t (t [1]) query_data])
response = requests.get(query_url, auth=my_auth, stream=True)
print(query_url, response)
return response
Then, 创建一个函数,该函数从上面的响应中获取响应,并从整个tweet的JSON对象中提取tweet的文本. After that, 它通过TCP连接将每条tweet发送到Spark Streaming实例(将在稍后讨论).
send_tweets_to_spark(http_resp, tcp_connection):
for line in http_resp.iter_lines():
try:
full_tweet = json.loads(line)
Tweet_text = full_tweet['text']
print("Tweet Text: " + tweet_text)
打印 ("------------------------------------------")
tcp_connection.send(tweet_text + '\n')
except:
e = sys.exc_info()[0]
print("Error: %s" % e)
Now, 我们将制作主要部分,它将使应用程序主机套接字连接,spark将与之连接. 我们将在这里配置IP为 localhost 因为所有这些都将在同一台机器和端口上运行 9009. Then we’ll call the get_tweets method, which we made above, 用于从Twitter获取tweet,并将其响应与套接字连接一起传递给 send_tweets_to_spark 发推特给斯巴克.
TCP_IP = "localhost"
TCP_PORT = 9009
conn = None
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.bind((TCP_IP, TCP_PORT))
s.listen(1)
等待TCP连接...")
conn, addr = s.accept()
print("Connected... Starting getting tweets.")
resp = get_tweets()
康涅狄格州send_tweets_to_spark(职责)
让我们构建Spark流媒体应用程序,它将对传入的tweet进行实时处理, 从中提取标签, 然后计算被提及的标签数.

首先,我们必须创建一个Spark Context的实例 sc,然后我们创建了流媒体上下文 ssc from sc 批处理间隔为两秒,将每两秒对接收到的所有流进行转换. 注意,我们已经将日志级别设置为 ERROR 以便禁用Spark写入的大部分日志.
We defined a checkpoint here in order to allow periodic RDD checkpointing; this is mandatory to be used in our app, 因为我们将使用有状态转换(将在同一部分后面讨论).
然后定义我们的主DStream数据流,它将连接到我们之前在端口上创建的套接字服务器 9009 看看那个港口的推特. DStream中的每条记录都是一条tweet.
从pyspark导入SparkConf,SparkContext
from pyspark.导入StreamingContext
from pyspark.sql import Row,SQLContext
import sys
import requests
# create spark configuration
conf = SparkConf()
conf.setAppName(“TwitterStreamApp”)
#使用上述配置创建spark context
sc = SparkContext(conf=conf)
sc.setLogLevel("ERROR")
#从上面的spark上下文创建流上下文,间隔大小为2秒
ssc = StreamingContext(sc, 2)
#设置检查点允许RDD恢复
ssc.检查点(“checkpoint_TwitterApp”)
# read data from port 9009
dataStream = ssc.socketTextStream(“localhost”,9009年)
现在,我们将定义转换逻辑. 首先,我们将所有的tweet分成单词,并将它们放入单词RDD中. 然后我们将只从所有单词中过滤标签,并将它们映射到一对 (hashtag, 1) and put them in hashtags RDD.
然后我们需要计算这个标签被提到了多少次. 我们可以用这个函数来做 reduceByKey. 这个函数将计算每批hashtag被提及的次数,i.e. 它将重置每批中的计数.
In our case, 我们需要计算所有批次的数量, 我们将使用另一个函数 updateStateByKey,因为该函数允许您在使用新数据更新RDD的同时维护RDD的状态. This way is called Stateful Transformation.
Note that in order to use updateStateByKey,您必须配置检查点,这就是我们在前一步中所做的.
# split each tweet into words
words = dataStream.flatMap(lambda line: line.split(" "))
#过滤单词以只得到标签,然后将每个标签映射为一对(hashtag,1)
hashtags = words.filter(lambda w: '#' in w).map(lambda x: (x, 1))
#将每个标签的计数添加到其最后计数
tags_totals = hashtags.updateStateByKey (aggregate_tags_count)
#对每个间隔内生成的每个RDD进行处理
tags_totals.foreachRDD(process_rdd)
#启动流计算
ssc.start()
#等待流完成
ssc.awaitTermination()
The updateStateByKey 接受一个函数作为参数 update function. 它在RDD中的每个项目上运行,并执行所需的逻辑.
在本例中,我们创建了一个名为 aggregate_tags_count that will sum all the new_values 并将它们添加到 total_sum 这是所有批次的总和,并将数据保存到 tags_totals RDD.
Def aggregate_tags_count(new_values, total_sum):
返回sum(new_values) + (total_sum或0)
Then we do processing on tags_totals 在每个批处理中使用RDD,以便使用Spark SQL Context将其转换为临时表,然后执行select语句,以便检索前十个带有其计数的hashtag并将其放入 hashtag_counts_df data frame.
def get_sql_context_instance (spark_context):
if ('sqlContextSingletonInstance'不在globals()中):
globals()['sqlContextSingletonInstance'] = SQLContext(spark_context)
返回全局()(“sqlContextSingletonInstance”)
def process_rdd(time, rdd):
Print ("----------- %s -----------" % str(time))
try:
#从当前上下文中获取spark sql单例上下文
Sql_context = get_sql_context_instance(rdd . txt).context)
# convert the RDD to Row RDD
row_rdd = rdd.map(lambda w: Row(hashtag=w[0], hashtag_count=w[1]))
# create a DF from the Row RDD
hashtags_df = sql_context.createDataFrame(row_rdd)
#注册数据框架为表
hashtags_df.registerTempTable("hashtags")
#使用SQL从表中获取前10个hashtag并打印出来
Hashtag_counts_df = sql_context.Sql ("select hashtag, hashtag_count from hashtags order by hashtag_count desc limit 10")
hashtag_counts_df.show()
#调用这个方法来准备前10个标签DF并发送它们
send_df_to_dashboard (hashtag_counts_df)
except:
e = sys.exc_info()[0]
print("Error: %s" % e)
Spark应用程序的最后一步是发送 hashtag_counts_df 数据帧到仪表板应用程序. 因此,我们将数据帧转换为两个数组,一个用于标签,另一个用于标签计数. 然后我们将通过REST API将它们发送到仪表板应用程序.
def send_df_to_dashboard(df):
#从数据框中提取标签并将其转换为数组
top_tags = [str(t.hashtag) for t in df.select("hashtag").collect()]
#从数据框中提取计数并将其转换为数组
tags_count = [p.hashtag_count for p in df.select("hashtag_count").collect()]
#初始化并通过REST API发送数据
url = 'http://localhost:5001/updateData'
Request_data = {'label': str(top_tags), 'data': str(tags_count)}
response = requests.post(url, data=request_data)
最后,这里是Spark Streaming运行和打印时的示例输出 hashtag_counts_df,您将注意到输出按照批处理间隔精确地每两秒钟打印一次.

现在,我们将创建一个简单的仪表板应用程序,它将由Spark实时更新. 我们将使用Python、Flask和 Charts.js.
首先,让我们用如下所示的结构创建一个Python项目 download and add the Chart.js file into the static directory.

Then, in the app.py 文件中,我们将创建一个名为 update_data, Spark将通过URL调用它 http://localhost:5001/updateData 以更新全局标签和值数组.
Also, the function refresh_graph_data 创建由AJAX请求调用,以返回新更新的标签和值数组作为JSON. The function get_chart_page will render the chart.html page when called.
从flask中导入flask、json、request
从flask中导入render_template
import ast
app = Flask(__name__)
labels = []
values = []
@app.route("/")
def get_chart_page():
global labels,values
labels = []
values = []
return render_template('chart.Html ', values=values, labels=labels)
@app.route('/refreshData')
def refresh_graph_data():
global labels, values
Print ("labels now: " + str(labels))
Print ("data now: " + str(values))
返回jsonify(sLabel=labels, sData=values)
@app.路线(“/ updateData”、方法=['文章'])
def update_data():
global labels, values
if not request.form or 'data' not in request.form:
return "error",400
labels = ast.literal_eval(request.form['label'])
values = ast.literal_eval(request.form['data'])
Print("收到的标签:" + str(标签))
Print ("data received: " + str(values))
return "success",201
if __name__ == "__main__":
app.运行(主机=“localhost”,端口= 5001)
中创建一个简单的图表 chart.html 文件,以便显示标签数据并实时更新它们. 如下面所定义的,我们需要导入 Chart.js and jquery.min.js JavaScript libraries.
In the body tag, 我们必须创建一个画布,并给它一个ID,以便在下一步使用JavaScript显示图表时引用它.
Top Trending Twitter Hashtags
Top Trending Twitter Hashtags
Online-gambling-service@shruntaizs.com
徐州赶集网
Sun-City-app-info@altqiye.com
Lottery-website-service@sogoking.com
太平洋时尚网奢品频道
重庆欣欣旅游网
iCAx开思论坛-
太阳城
Crown-Sports-official-website-sales@hunan263.com
New-Portuguese-online-customerservice@m3csl.net
赌博网站
QQ号码测运气
hg皇冠
Sun-City-Group-billing@turuntilataksit.net
诺安基金
A-surname-customerservice@nhllivebetting.com
中国心理学会
劲胜精密
中国科学评价研究中心
太阳城
中国设计手绘技能网
太原师范学院教务处
泉州安全教育平台
青蛙王子
常州装饰网
惠州本地宝
求医网图片频道
远洲股份
UC云
易宝金融
《侠客风云传》官网
海参之家
全国征兵网
卜蜂莲花
江苏新闻周刊网
现在,让我们使用下面的JavaScript代码构建图表. First, we get the canvas element, 然后我们创建一个新的图表对象,并将canvas元素传递给它,并定义它的数据对象,如下所示.
请注意,数据的标签和数据受到标签和值变量的约束,这些变量是在调用时呈现页面时返回的 get_chart_page function in the app.py file.
最后剩下的部分是配置为每秒执行一个Ajax请求并调用URL的函数 /refreshData, which will execute refresh_graph_data in app.py 并返回新更新的数据,然后更新呈现新数据的char.
让我们按照下面的顺序运行这三个应用程序: 1. Twitter App Client. 2. Spark App. 3. Dashboard Web App.
然后,您可以使用URL访问实时仪表板
现在,你可以看到你的图表正在更新,如下所示:
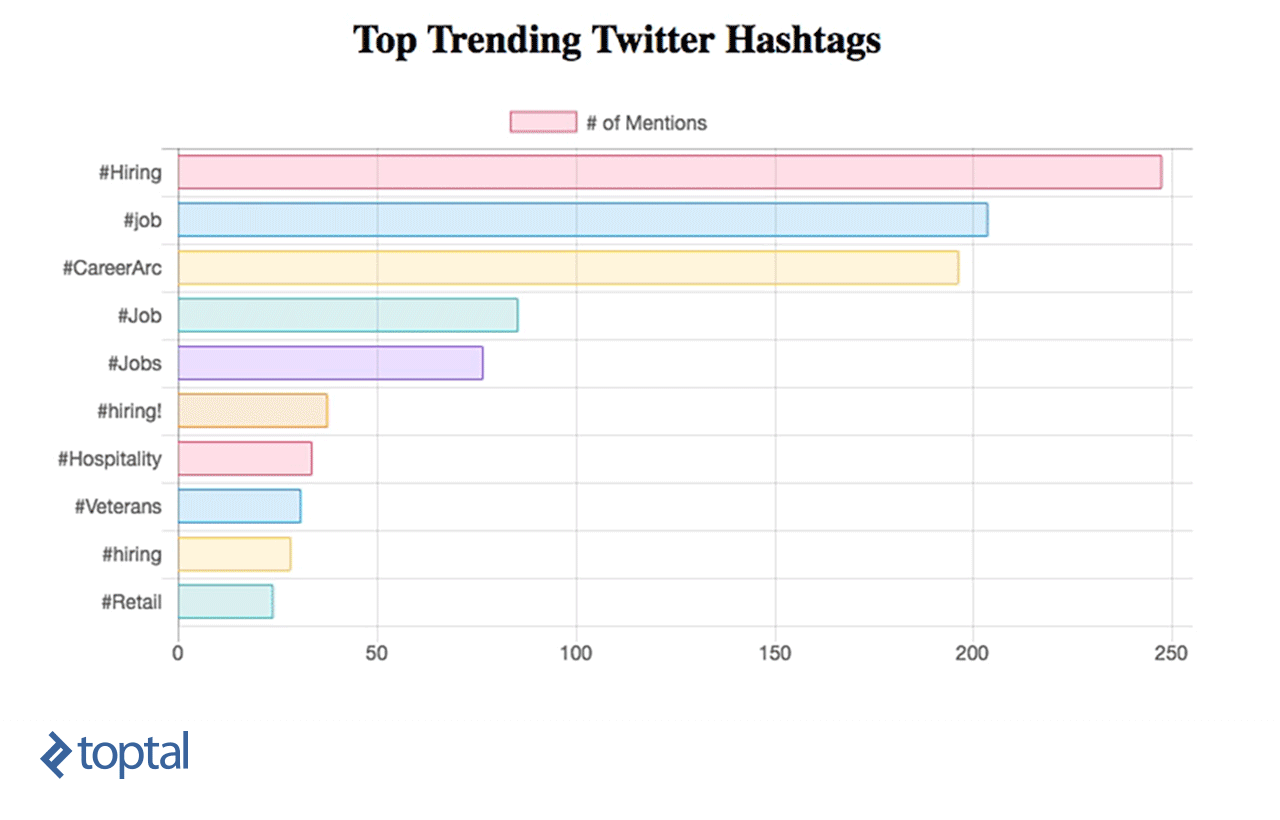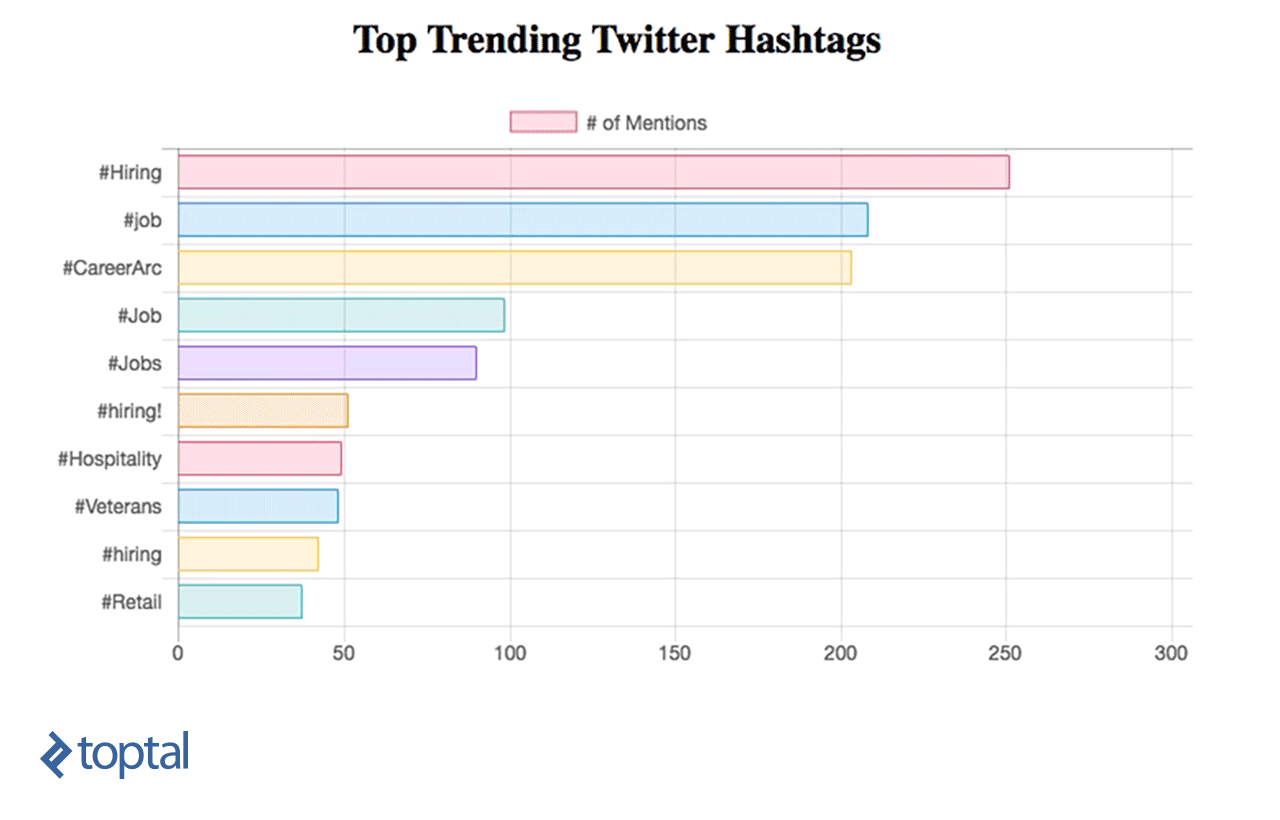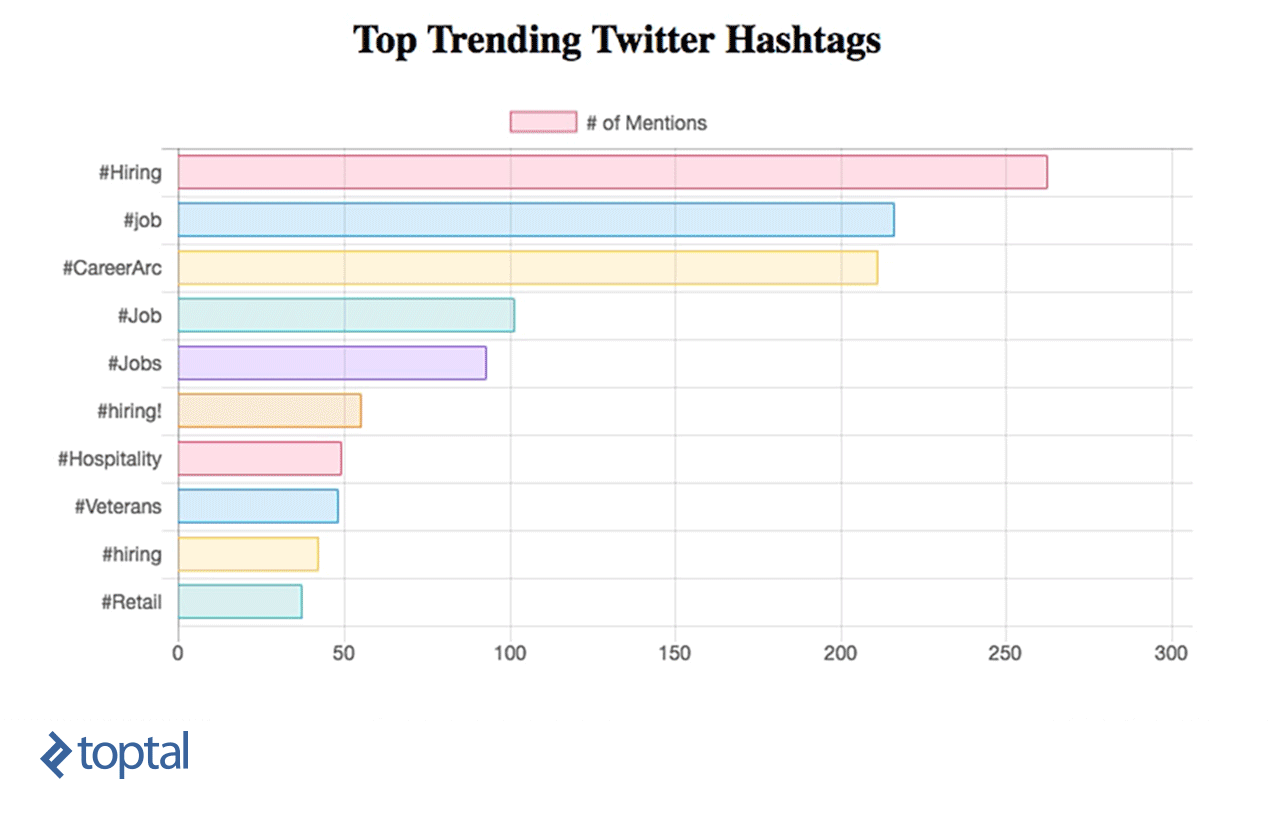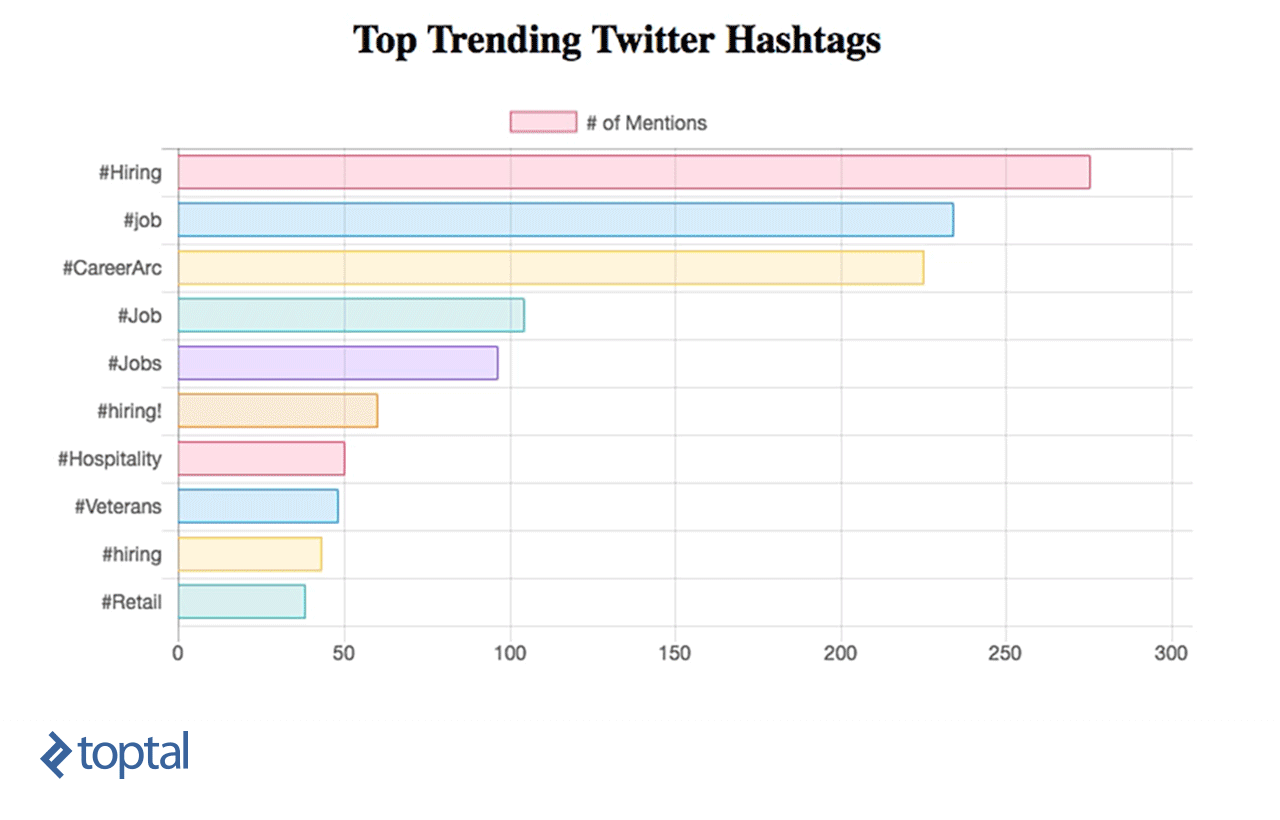
我们已经学习了如何使用Spark Streaming实时对数据进行简单的数据分析,并使用RESTful web服务将其直接与简单的仪表板集成. From this example, 我们可以看到火种有多强大, 因为它捕获了大量的数据流, transforms it, 并从中提取有价值的见解,这些见解可以很容易地用于快速做出决策. 有许多有用的用例可以实现,它们可以服务于不同的行业, like news or marketing.

News industry example
我们可以追踪最常被提及的标签,了解人们在社交媒体上谈论最多的话题. Also, 我们可以跟踪特定的标签和他们的推文,以便了解人们对世界上特定话题或事件的看法.
Marketing example
我们可以收集推特流, by doing sentiment analysis, 对他们进行分类,确定人们的兴趣,以便为他们提供与他们的兴趣相关的服务.
Also, 有很多用例可以专门应用于大数据分析,可以服务于很多行业. 要了解更多的Apache Spark用例,我建议您查看我们的 previous posts.
我鼓励您阅读更多关于Spark Streaming的内容 here 为了更多地了解它的功能,并对数据进行更高级的转换,以便实时使用它获得更多的见解.
它可以进行大规模的快速数据处理、流媒体和机器学习.
它可以用于数据转换, predictive analytics, 以及大数据平台的欺诈检测.
Twitter allows you to get its data using their APIs; one of ways that they make available is to stream the tweets in real time on search criteria that you define.
经过认证的Spark开发人员,拥有CEng学位和商业智能文凭, Hanee开发了拥有数百万日用户的企业应用程序.
 作者都是各自领域经过审查的专家,并撰写他们有经验的主题. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.
作者都是各自领域经过审查的专家,并撰写他们有经验的主题. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.世界级的文章,每周发一次.
世界级的文章,每周发一次.
Join the Toptal® community.
